No products in the cart.
HOT






NVIDIA A30 Enterprise Tensor Core 24GB 165W
✓ GPU memory: 24GB HBM2
✓ GPU memory bandwidth: 933GB/s
✓ Interconnect: PCIe Gen4: 64GB/s, Third-gen NVLINK: 200GB/s**
✓ Form factor: Dual-slot, full-height, full-length (FHFL)
✓ Max thermal design power (TDP): 165W
✓ Multi-Instance GPU (MIG): 4 GPU instances @ 6GB each, 2 GPU instances @ 12GB each, 1 GPU instance @ 24GB
✓ Virtual GPU (vGPU) software support: NVIDIA AI Enterprise, NVIDIA Virtual Compute Server
✓ Warranty: 2 year manufacturer repair or replace
Ships in 5 days from payment. No returns or cancellations. All sales final.
Description
-
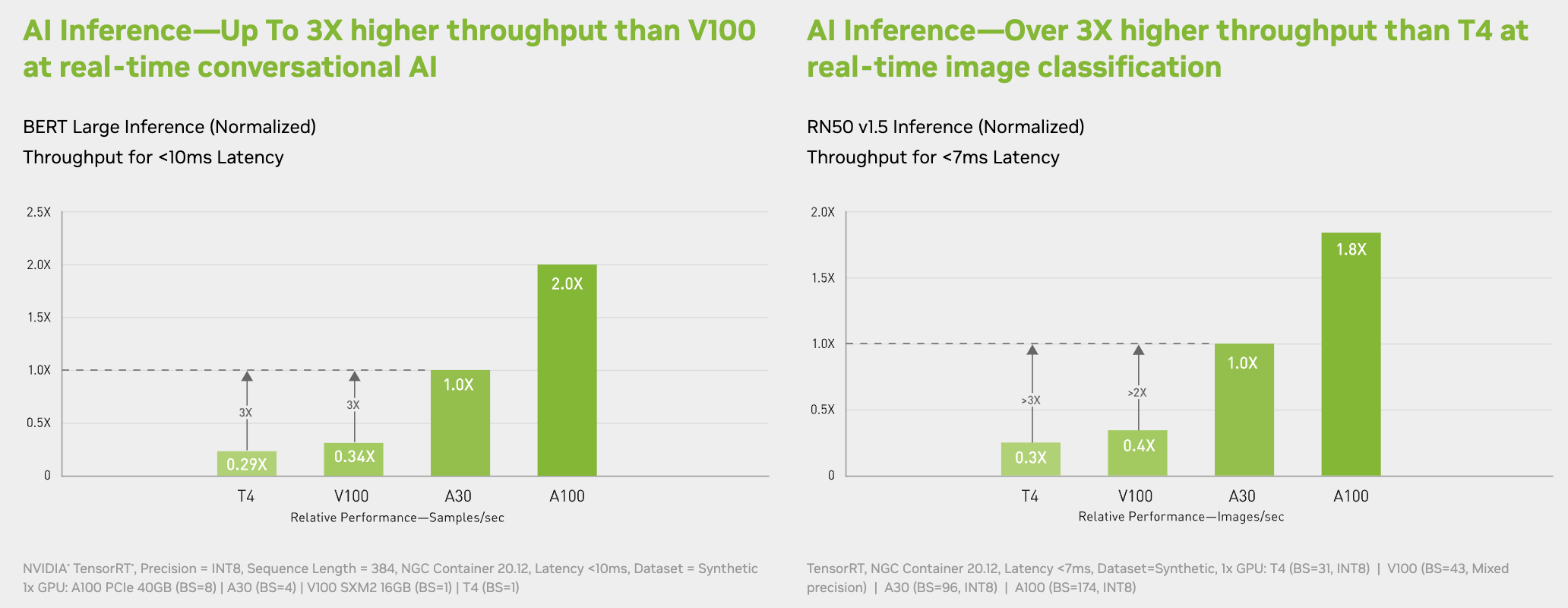
AI Inference and Mainstream computing for Every Enterprise
Bring accelerated performance to every enterprise workload with NVIDIA A30 Tensor Core GPUs. With NVIDIA Ampere architecture Tensor Cores and Multi-Instance GPU (MIG), it delivers speedups securely across diverse workloads, including AI inference at scale and high-performance computing (HPC) applications. By combining fast memory bandwidth and low-power consumption in a PCIe form factor—optimal for mainstream servers—A30 enables an elastic data center and delivers maximum value for enterprises.
Deep Learning Training
AI Training—Up to 3X higher throughput than v100 and 6X higher than T4
Training AI models for next-level challenges such as conversational AI requires massive computing power and scalability.
NVIDIA A30 Tensor Cores with Tensor Float (TF32) provide up to 10X higher performance over the NVIDIA T4 with zero code changes and an additional 2X boost with automatic mixed precision and FP16, delivering a combined 20X throughput increase. When combined with NVIDIA® NVLink®, PCIe Gen4, NVIDIA networking, and the NVIDIA Magnum IO™ SDK, it’s possible to scale to thousands of GPUs.
Tensor Cores and MIG enable A30 to be used for workloads dynamically throughout the day. It can be used for production inference at peak demand, and part of the GPU can be repurposed to rapidly re-train those very same models during off-peak hours.
NVIDIA set multiple performance records in MLPerf, the industry-wide benchmark for AI training
A30 Tensor Core GPU Specifications
Brand
Nvidia
Related products
HOT SALE

AMD Radeon Pro Radeon Pro VII Graphic Card 16 GB HBM2 Full-height 100506163
Original price was: $1,290.00.$1,088.00Current price is: $1,088.00.HOT SALE

NVIDIA 8X DGX H100 Deep Learning Console
Original price was: $415,000.00.$322,000.00Current price is: $322,000.00.HOT SALE

XFX MERCURY Magnetic Air Radeon RX 7900 XTX 24GB GDDR6 PCI Express 4.0 x16
Original price was: $915.00.$788.00Current price is: $788.00.SALE

SAPPHIRE NITRO+ Radeon RX 7900 XTX OC 24GB Graphics Card, 384 bit GDDR6G PCI-Express 4.0 x16 ATX Video Card
Original price was: $1,370.00.$1,099.00Current price is: $1,099.00.HOT SALE

ASRock Radeon RX 6800 XT Phantom Gaming Graphics Card with 16GB GDDR6, AMD RDNA 2
Original price was: $430.00.$365.00Current price is: $365.00.HOT SALE
